Right off the bat; I don't know. All I know is that it's complicated.
I have this page which is just a blog post page. It's entirely rendered on the server, comments and all. At the time of writing, the total size of the HTML document is 119KB (30KB gzipped). If you remove all the comments, which makes up the bulk of the HTML it reduces down to 31KB (7KB gzipped). Fair enough. That's 23KB less to download. But, does it matter (much)?
Downloading
First of all, I noticed this:

WebPagetest with iPhone 6, 4G on the same US coast as the datacenter
That's a WebPagetest using iPhone 6 on 4G and, lemme emphasize this, it took 126ms to download the HTML document. If you subtract "DNS Lookup" (283ms), "Initial Connection" (1013ms), and "SSL Negotiation" (733ms) it took 684ms serve the file, download it, and parse it. Remember, this is all on 4G. Pretty fast. In conclusion, it's probably not too much HTML in that page to download. This downloadingness is fraction of the total "web performance cost". Let's dig deeper.
Note! With WebPagetest all those numbers like DNS Lookup, Initial Connection and SSL Negotiation are wildly unpredictable between tests. Chances are, the numbers are very different the next time you run a test using the exact same input. Who knows. Deep internet plumbings beyond the control of WebPagetest.
Note! I ran it one more time with the exact same parameters and this time it was 535ms (instead of 684ms) to serve, download, and parse.
Parsing & layout
Parsing is hard to measure but here's what I found when using the Google Chrome dev tools:
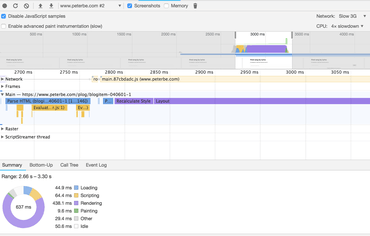
Google Chrome Performance devtools
It says it took...
- parsed HTML - 94ms
- recalculate style - 43ms
- layout - 386ms
That's half a second just loading and rendering. Definitely sucks. But note, this test uses 4x CPU slowdown and 3G simulation. So perhaps it's not so bad.
Let's try again with a smaller HTML document
So I butchered up a hybrid version that has almost the same HTML except all but 1 of those 166'ish div.comment DOM nodes. It's now 31KB (7KB gzipped´) to download instead of 119KB (30KB gzipped).
Same WebPagetest parameters but now this this smaller HTML document:

WebPagetest with a much smaller HTML footprint
Now it says it only took 39ms to download and 232ms (it was 684ms before) to serve the file, download it, and parse it. Interesting!
Note! I ran it one more time with exact same parameters and this time it was 237ms (instead of 232ms) to serve, download, and parse.
Clearly it's working. The smaller the HTML document the faster it performs. No surprise. But stick around for the conclusion.
Parsing & layout with a smaller HTML document
Check this out:
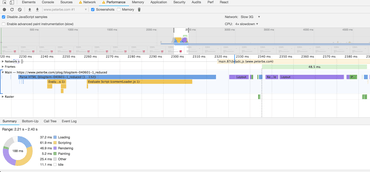
Google Chrome Performance devtools (smaller HTML document)
It says it took...
- parsed HTML - 91ms
- recalculate style - 6ms
- layout - 29ms
Mind you, all of these numbers are at the mercy of what my laptop is up to at the moment as it can affect Chrome's rendering if it has, at that moment, less (or more) access to CPU and memory caching.
Either way, it parses + layout in 126ms instead of 523ms for the larger HTML document.
Side-by-side
The best test to see how much faster the smaller HTML document variant is, is to compare them side-by-side. It looks like this:
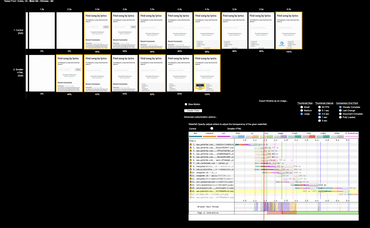
Visual comparison on WebPagetest (using 4G)
Two major takeaways from this:
- The smaller HTML version starts rendering half a second before the original one.
- The complete time favors the smaller HTML version by 2.5 seconds but that's possibly influenced by the ads that load more than any slow layout rendering.
- This is using 4G which isn't unheard of but definitely much less common than better speeds.
Here they are compared on "Desktop" which appears to give the smaller HTML version a 0.2 second advantage:

Visual comparison on WebPagetest (using "Desktop")
And here are the Lighthouse reports side-by-side:
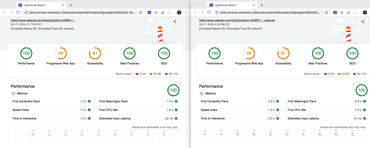
Side-by-side using Lighthouse
Discussion
The above concludes rather unsurprisingly that a smaller HTML footprint downloads, parses and lays out quicker.
The killer reason that page is so large, with all those comments rendered in the original HTML is simple: SEO. Google loves comments because comments indicate that the page is thriving and a place where people go, spend time, and stick around. I've experimented with this in the past and found that if I make the HTML document smaller (or loading the rest after document load) the SEO takes a big hit. Yes, Google's bot renders with JavaScript but not always and even if it does, I assume it's smart enough to appreciate that content that is loaded (async or post-DOMContentLoad) is less important and thus not what the page is about.
Regarding SEO, we know that Google loves fast sites. Especially for mobile. But content is still king my gut tells me. Left as an exercise to the reader to take a stand on this.
Another problem with lazy loading the comments (or whatever else might be applicable to your site) is that it might cause "flicker". I put that word in quote because sometimes flicker is literally visual flicker and sometimes it's moments of browser sluggishness. The XHR request and the subsequent post-rendering will cause a bunch of work that strains the browser and might make it unpleasant when your eyes and brain is in the midst of committing to consuming it.
Basically, there are significant real benefits of not trying to squeeze every little millisecond out by making the HTML smaller upfront. Remember the fact that the "smaller HTML" version in this test is drastic. I butchered it from 119KB to 31KB which might be so drastic that it's not necessarily applicable at all. In other words, had I reduced the HTML size by just 20% it might not even register on the performance graph but could be significant in terms SEO keywords.
Conclusion
The majority of the time spend making a web page useful to a user is a sum of all sorts of metrics. The size of the HTML document does matter but remember that it's just one of multiple aspects to watch out for.
In conclusion, it's complicated and depends on your needs and context. I hope you can benefit a little bit from the metrics above.













