tl;dr; The ideal web performance, with regards to CSS, is to inline the minimal CSS and lazy load the rest after load.
Two key things to understand/appreciate:
-
The fastest performing web page is one that isn't blocked on rendering.
-
You use some CSS framework kitchen sink because you're not a CSS guru.
How to deal with this?
Things like HTTP2 and CDNs and preload are nice because they make the network lookup for your main.88c468ef.css file as fast as possible. But what's even faster is to include the CSS with the HTML that the server responds in the first place. Why? Because when the browser downloads your HTML (e.g. GET /) as it parses the HTML document it sees that <link rel="stylesheet" href="/main.88c468ef.css"> there and decides to not render any DOM to screen until that CSS file has been downloaded and parsed. It does this because it doesn't want to have to paint the DOM (as it would look like without CSS) and then repaint the DOM again, this time with CSS rules.
Point number 2 basically boils down to the likely fact that your app depends on somecssframework.min.css like Bootstrap, Bulma or Foundation. They're large blobs of CSS for doing all sorts of types of HTML (e.g. cards, tables, navbar menus etc.). These CSS frameworks are super useful because they make your app look pretty. But they're usually big. Really big.
Popular CSS frameworks:
| Framework |
Size |
Gzipped |
| bootstrap.min.css |
122K |
18K |
| foundation.min.css |
115K |
16K |
| semantic.min.css |
553K |
93K |
| bulma.min.css |
141K |
18K |
Actually the size difference isn't hugely important. What's important is that it's yet another thing that needs to be downloaded before the page can start to render. If the URL is in the user's cache, great. Even better, if it's cached by a service worker. However if you care about loading performance (judging by the fact that you're still reading), you know that a large majority of your visitors only come to your site sometimes (according to Google Analytics, 92.7% of my visitors are "new visitors"). Perhaps from a Google search. Or perhaps they visit sometimes but rarely enough that by the time they return their browser cache will have "moved on" and reset (to save disk space) what was previously cached.
CSS is a render blocking resource
See Ilya Grigorik's primer on Render Blocking CSS.
It's also easy to demonstrate. Check out this Webpagetest Visual Comparison that compares two pages that are both styled with bootstrap.min.css except one of them uses a piece of JavaScript at the bottom of the page that enables the stylesheet after the page has loaded.
So if it's blocking. What to do about it? Well, make it not blocking. But how?
Solution 1
The simplest solution is to simply move any <link rel="stylesheet" href="bootstrap.min.css"> out of the <head> and put them just before the </body> tag. Here's an example of that.
It's valid HTML5 and seems to work just fine in Safari iOS. The only problem is that pesky "Flash of Unstyled Content" (aka. "FOUT") effect where the user is presented with the page very briefly without any styling, then the whole page re-renders onces the stylesheets have loaded. Chrome and iOS actually block the rendering still. So it's not like JavaScript whereby putting it late in the DOM. In other words, not really a good solution at all.
You can see in this Webpagetest that the "Start render" happens after the .css files have been loaded and parsed.
Solution 2
With JavaScript you can put in code that's definitely going to be executed after the rendering starts and, also, after the first rendering is finished (i.e. "DOM Content Loaded").
This technique is best done with loadCSS which can be done really well if you tune it. In particular the rel="preload" feature is getting more and more established. It used to only work in Chrome and Opera but will soon work in Firefox and iOS Safari too. Note, loadCSS contains a polyfill solution to the rel="preload" thing.
The basics is that you load a piece of JavaScript late which, as soon as it can, puts the <link rel="stylesheet" href="bootstrap.min.css"> into the DOM. You still have the Flash of Unstyled Content effect to confront and that's annoying.
Here's an example implementation. It uses the scripts and techniques laid out by filamentgroup's loadCSS.
It works and the rel="preload" is a bonus for Chrome and Opera users because once the JavaScript "kicks in" the network loading is quite possible already done. As seen in this Webpagetest using Chrome the .css files start downloading before the lazyloadcss.js file has even started downloading.
It's not as hot in Firefox because all the .css files downloading is delayed until after the lazyloadcss.js has loaded and executed.
Solution 3
Just inline all the CSS. Instead of <link rel="stylesheet" href="bootstrap.min.css"> you just make it inline. Like:
<style type="text/css">
@media print{*,::after,::before{text-shadow:none!important;box-shadow:none!important}......
</style>
All 123KB of it. Why not?! It has to be downloaded sooner or later anyway, might as well nip it in the bud straight away. The Flash of Unstyled Content problem goes away. So does the problem of having to load JavaScript tricks to make the CSS loading non-blocking.
The obvious and immediate caveat is that now the whole HTML document is huge! In this example page the whole HTML document is 127KB (20KB gzipped) whence the regular one is 4.1KB (1.4KB gzipped). And if your visitors, if you're so lucky, click on any other internal link that's another 127KB that has to be downloaded again.
The biggest caveat is that downloading a large HTML document is bad because no other resources (images for example) can be downloaded in parallel whilst the browser is working on rendering the page with what it's downloaded so far. If you compare this Webpagetest with the regular traditional one, you can see that it takes almost 354ms to download the HTML with all CSS inlined compared to 262ms when the CSS was linked. That's roughly 100ms wasted where the browser could start download other resources, like images.
Solution 4
Solution 3 was kinda good because it avoided the Flash of Unstyled Content and it avoided all extra resource loading. However, we can do better.
Instead of inlining all CSS, how about we take out exactly only the CSS we need out of bootstrap.min.css and just inline that. Then, after the page has loaded, we can download the rest of bootstrap.min.css and that way it's ready with all the other selectors and stuff it needs as the page probably changes and morphs depending on interactive JavaScript which is stuff that can and will happen after the initial load.
But how do you know exactly which CSS you need for that initial load? Really, you don't. You have two options:
-
Manually inspected what DOM elements you have in your initial HTML and start slowly plucking that out of the Bootstrap CSS file.
-
Automate the inspection of what DOM elements you have in your initial HTML.
Before we dig deeper into the how to automate the inspection let's look at what it'd look like: This page and when Webpagetested. What's cool here is that the DOM is ready in 265ms (it was 262ms when there was no linked CSS).
Notice that there's no Flash of Unstyled Content. No external dependencies. It's basically an inline <style> block with exactly the selectors that are needed and nothing more. The HTML is larger, at 13KB (3.3KB gzipped), but remember it was 4.1KB when we started and the solution where we inlined everything was 127KB.
The immediate problem with this is that we're missing some nice CSS for things that haven't been needed yet. For example, there might be some JavaScript that changes the DOM based on something the user does with the page. For example, clicking on something that adds more elements to the DOM. Or, equally likely, after the the DOM has loaded, an XHR query is made to download some data and display it in a way that needs CSS selectors that weren't included in the minimal set.
By the way, this very blog post builds on this solution. If you're on your desktop browser you can view source and see that there's only inline style blocks.
Solution 5
This builds on Solution 4. The HTML contains the minimal CSS needed for that first render and as soon as possible we additionally download the whole bootstrap.min.css so that it's available if/when the DOM mutates and needs the full CSS not in the minimal CSS.
Basically, let's take Solution 2 (JavaScript lazy loads in the CSS) + Solution 4 (the minimal CSS inlined). Here is one such solution
And there we have it! The ideal solution. The only thing remaining is to verify that it actually makes a difference.
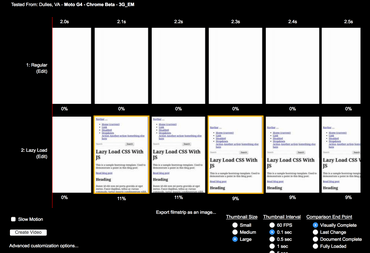
The Webpagetest Final Showdown
We have 5 solutions. Each one different from the next. Let's compare them against each other.
Here it is in its full glory
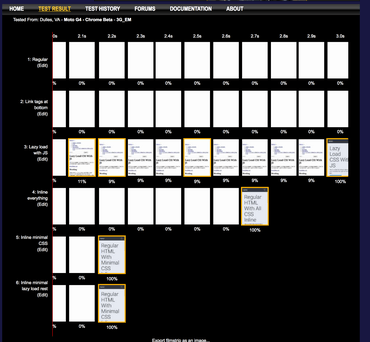
(image if you can't open the Webpagetest page right now)
What we notice:
- The regular do-nothing solution is 50% slower than the best solution. 3.2 seconds verus 2.2 sceonds.
- Putting the
<link rel="stylesheet" ...> tags at the bottom of the document doesn't work in Chrome and doesn't do anything good.
- Lazy loading the CSS with JavaScript (with no initial CSS) displays content very early but the repaint means it takes unnecessarily longer to load the whole thing.
- The ideal solution (Solution 5) loads as fast, visually, as Solution 4 but has the advantage that all CSS is there, eventually.
- Inlining all CSS (Solution 3) is only 23% slower than the ideal solution (Solution 5). But, it's much easier to implement. Seriously consider this if your tooling is limited.
Conclusion
One humbling thing to notice is that the difference isn't actually that huge. In this particular example we managed to go from 3.2 seconds to 2.2 seconds (using a 3G connection). The example playground used in this experiment is very far from a real site. Most possibly, a real site is a lot more complex and full of lots more potential bottlenecks that slows things down. For example, instead of obsessing over the CSS payload, perhaps you can make a bigger impact by simply dropping some excessive JavaScript plugins that might not necessarily be needed. Or you can focus on your 2.5MB total of big images.
However, a key ingredient to web performance is to leverge the loading time the best possible way. If you get the CSS un-blocking rendering right, your users' browsers can spend more time, sooner, on other resources such as images and XHR.
UPDATE March 2018
A lot of this work of figuring out the minimal CSS from a DOM has now been put in a rapidly maturing and well tested Nodejs project called minimalcss.










{kind=link}